
De wereldwijde internetinfrastructuur kreeg op 18 november 2025 een stevige klap te verwerken toen Cloudflare urenlang problemen had met het verwerken van kernverkeer. Voor datacenters en online diensten, die in hoge mate steunen op Cloudflare’s CDN- en beveiligingsdiensten, was de impact direct zichtbaar: foutcodes, vastlopende authenticaties en haperende dashboards. In een uitgebreide blogpost blikte CEO Matthew Prince terug op wat hij omschreef als “de ergste storing sinds 2019” en legde hij uit hoe een ogenschijnlijk kleine databasewijziging kon uitgroeien tot een verstoring die het wereldwijde internetverkeer beïnvloedde.
Een storing die zich vreemd gedroeg
De problemen begonnen om 11:20 UTC, toen gebruikers foutpagina’s te zien kregen voor sites die via Cloudflare liepen. Al snel bleek dat het verkeer in de kernproxy – het systeem dat elk inkomend verzoek verwerkt voordat het naar de juiste dienst wordt geleid – niet goed meer functioneerde. In zijn blog schrijft Prince dat het Cloudflare-team aanvankelijk dacht aan een grootschalige DDoS-aanval, mede omdat tegelijkertijd ook de statuspagina uitviel, een combinatie die volgens hem “in eerste instantie alle alarmbellen deed afgaan”.
Wat volgde was een onvoorspelbaar patroon van uitval en herstel: het systeem leek de ene minuut te stabiliseren, om enkele minuten later opnieuw te falen. De reden bleek later verbluffend technisch maar tegelijk eenvoudig: het configuratiebestand van Cloudflare’s botbeheersysteem werd elke vijf minuten opnieuw samengesteld door een ClickHouse-databasecluster dat net een toegangsrechtenupdate kreeg. Alleen de shards waar die update al actief was, leverden foutieve data op. Daardoor wisselde het netwerk voortdurend tussen goede en slechte configuraties.
De oorzaak: een configuratiebestand dat te groot werd
De kern van de storing lag in het bestand dat wordt gebruikt om bots te detecteren. Dit zogeheten ‘feature-bestand’ voedt een machine-learningmodel dat voor elk verzoek bepaalt hoe waarschijnlijk het is dat het van een bot afkomstig is. Door de databasewijziging ontstonden er duplicaten in de dataset, waardoor het bestand meer dan twee keer zo groot werd. De software die de configuraties verwerkt, heeft een harde limiet op het aantal kenmerken om geheugenproblemen te voorkomen. Die limiet werd overschreden, waarna de proxysoftware in paniek stopte.
Prince noemt dit een fout in het ontwerp: “Onze systemen moeten bestand zijn tegen verkeerde of onverwachte input, zeker als die input uit onze eigen infrastructuur komt.”
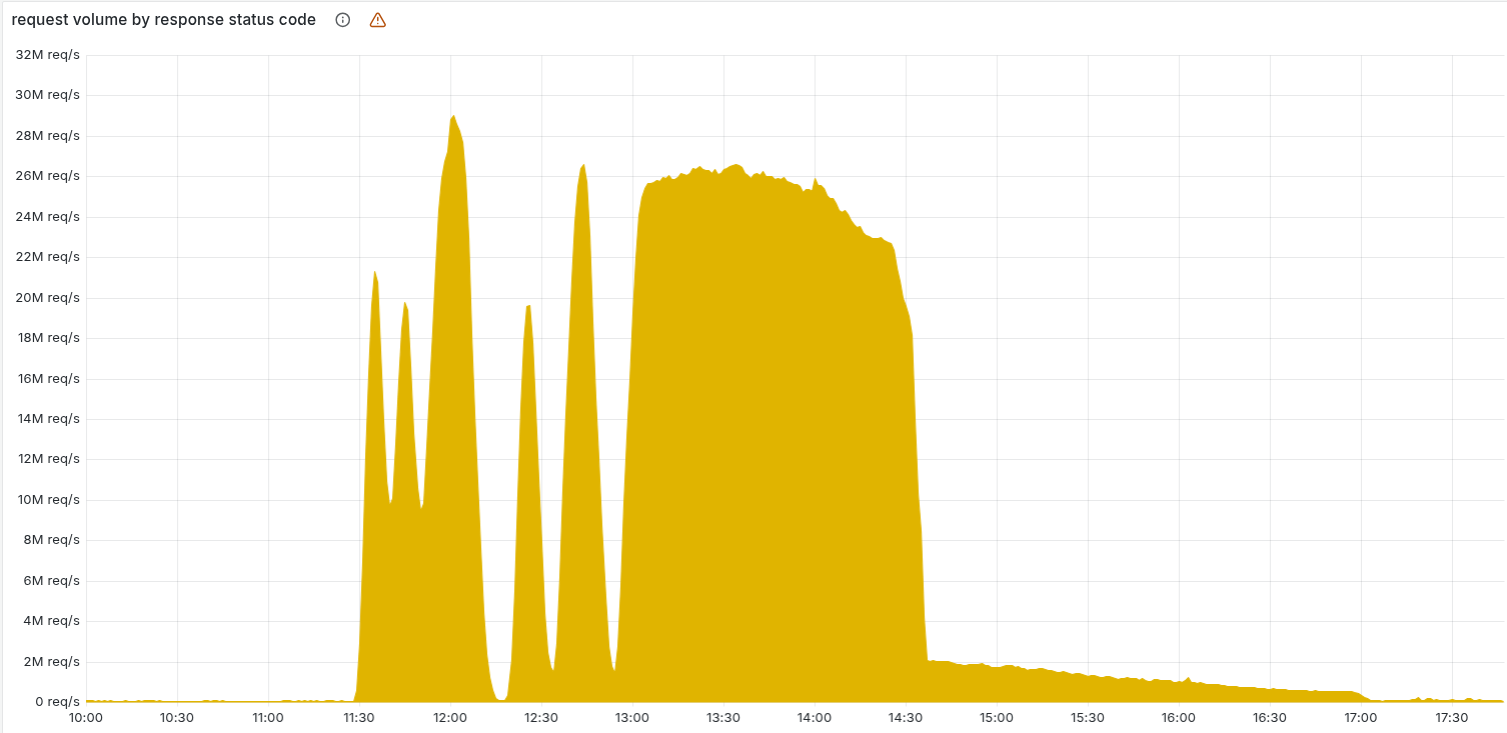
Het gevolg was dat de kernproxy voor een aanzienlijk deel van het verkeer 5xx-fouten begon terug te geven. Voor diensten die op die proxy steunen – zoals Workers KV, Access en Turnstile – had dit verstrekkende gevolgen. Authenticaties liepen vast, dashboards konden niet geladen worden en sommige botscore-regels bij klanten sloegen volledig door.
Patchwork om het verkeer overeind te houden
Rond 13:05 wist Cloudflare de impact te beperken door Workers KV en Access tijdelijk te laten terugvallen op een oudere versie van de proxy. Dat was geen volledige oplossing, maar genoeg om het aantal foutmeldingen te verlagen.
Het definitieve herstel kwam pas toen het team de distributie van nieuwe configuratiebestanden stopzette en handmatig een eerdere, goede versie injecteerde. Om 14:30 UTC stroomde het grootste deel van het verkeer weer normaal. Daarna volgden nog uren waarin systemen die in een slechte toestand waren geraakt opnieuw moesten worden opgestart of opgeschoond. Om 17:06 verklaarde Prince alle diensten weer volledig operationeel.
Wat het incident betekent voor datacenterprofessionals
Voor datacenters en operators toont dit incident hoe kwetsbaar zelfs hooggeautomatiseerde infrastructuurketens kunnen zijn wanneer een intern systeem op onverwachte wijze faalt. Het laat ook zien hoe breed de effecten kunnen uitwaaieren: niet alleen latency en foutcodes, maar ook authenticatie, debuggingtools en zelfs monitoringplatforms kunnen rol na rol omvallen wanneer de kernproxy hapert. Prince erkent dit openlijk: “Onze rol in het internetecosysteem betekent dat elke storing onacceptabel is. Dat ons netwerk gedurende enige tijd geen verkeer kon doorsturen, is pijnlijk voor ieder lid van ons team.”
Daarnaast benadrukt het incident het belang van grenzen binnen configuratiesystemen. De limieten die waren ingesteld om geheugen te beschermen, bleken uiteindelijk de directe trigger voor de fouten. Dit type beschermingsmechanisme is gangbaar in omgevingen met hoge doorvoervolumes en lage latency-eisen, maar kan ongewenste neveneffecten hebben wanneer bronbestanden onbedoeld groeien.
Maatregelen om herhaling te voorkomen
Cloudflare kondigt in de blog een reeks maatregelen aan om het systeem robuuster te maken. Het bedrijf wil de inputvalidatie van interne configuratiebestanden versterken, globale noodstopschakelaars introduceren en foutafhandeling beter isoleren zodat kernelpanic-achtige situaties in de proxy in de toekomst worden vermeden. Ook worden limieten en faalmodi van alle proxy-modules opnieuw geëvalueerd.
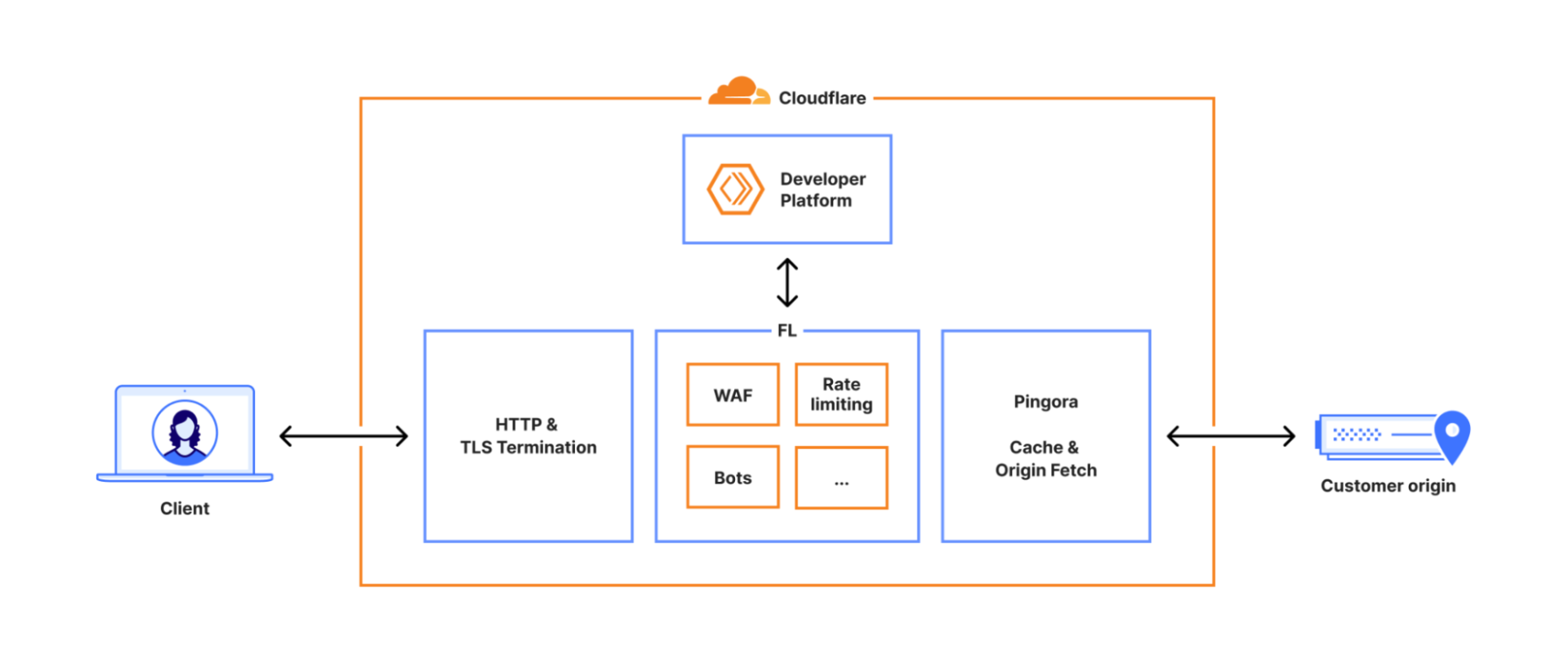
Prince zegt hierover dat het incident “nieuwe, veerkrachtiger systemen zal opleveren, net zoals eerdere storingen dat hebben gedaan.” Het past in een bredere Cloudflare-strategie om de stap te maken naar FL2, een nieuwe generatie van de kernproxy. Deze proxy werd eveneens getroffen, maar op andere manieren dan de oude FL-engine. Het incident biedt het bedrijf daarmee waardevolle inzichten in beide platforms.
Een zeldzame maar ingrijpende storing
Hoewel Cloudflare de afgelopen jaren herhaaldelijk kleine storingen had die functies of dashboards tijdelijk uitschakelden, is het lang geleden dat het kernverkeer in deze mate werd geraakt. Datacenters en specialisten zullen vooral geïnteresseerd zijn in de vraag hoe Cloudflare structureel kan voorkomen dat fouten in configuratiegeneratie zich razendsnel wereldwijde verspreiden. De blog van Prince biedt daar nog geen definitieve antwoorden op, maar wel de eerste contouren.
Met een uitgebreid excuus sluit hij zijn blog af: “Namens het hele team willen we ons verontschuldigen voor de problemen die we vandaag op internet hebben veroorzaakt.”
Voor een infrastructuur die als fundament dient voor een groot deel van het web is dat geen overbodige luxe. Maar uiteindelijk gaat het er vooral om wat Cloudflare nu leert van dit incident – en hoe het netwerk wordt versterkt voordat een vergelijkbare fout opnieuw onverwacht toeslaat.
0 Reacties